Imagine the world’s internet backbone collapsing in a day.
Whether it’s due to human error, a catastrophic software bug, a rogue computer virus, or outright kinetic warfare, what happens to Bitcoin if the physical internet exchange hubs that connect the world suddenly go dark?
If Frankfurt, London, Virginia, Singapore, and Marseille were to go offline simultaneously, Bitcoin splits into three partitions.
Traffic across the Atlantic, the Mediterranean, and the main trans-Pacific routes would stall, leaving the Americas, Europe, Africa, the Middle East, and Asia and Oceania to view history separately until links are restored.
Block production continues inside each partition according to the hashrate that remains reachable.
With a 10-minute global target, a region that holds 45 percent of the hashrate produces roughly 2.7 blocks per hour, 35 percent produces about 2.1 blocks, and 20 percent produces about 1.2 blocks. Because nodes cannot exchange headers or transactions across partitions, each region advances a valid chain unaware of the others.
The result is a natural fork depth that grows with time and with the distribution of hashrate.
The partitioned cadence makes the divergence mechanical. Let’s assign rough hashrate averages to each region. For our modeling, we will use 45%, 35%, and 20% as our baseline distribution for the Americas, Asia and Oceania, and Europe and Africa, respectively.
An Americas cohort would add about six blocks every two hours, while Asia and Oceania would roughly add four to five blocks per hour, and Europe and Africa would add around two to three blocks per hour.
After one hour, the ledgers would already differ by double-digit blocks.
After half a day, gaps expand into the low hundreds.
After a full day, the chains differ by hundreds of blocks, which is beyond the range of routine reorganizations and forces services to treat regional confirmations as provisional only.
Local mempools split immediately. A transaction broadcast in New York would not reach Singapore, so receivers outside the sender’s partition would see nothing until routes recover.
Within each partition, fee markets turn local. Users compete for limited blockspace against the regional hashrate, so fees rise fastest where hashrate is smallest and demand remains high.
Exchanges, payment processors, and custodial wallets typically pause withdrawals and on-chain settlement when confirmations lose global finality, and Lightning counterparties face uncertainty around commitment transactions that confirm on minority partitions.
When routes are returned, nodes initiate an automatic reconciliation.
Each node compares chains and reorganizes to the valid chain with the most cumulative work.
The practical costs fall into three buckets:
- The depth of reorganizations that invalidate minority-partition blocks.
- The work of rebroadcasting and reprioritizing transactions that were previously “confirmed” only on a losing branch.
- The operational checks that exchanges and custodians perform before reopening.
In a 24-hour fracture, dozens to hundreds of minority-partition blocks can be orphaned upon recovery, and services require additional hours to rebuild mempools, recalculate balances, and re-enable withdrawals.
Full economic normalization often lags protocol convergence because fiat rails, compliance checks, and channel management require human review.
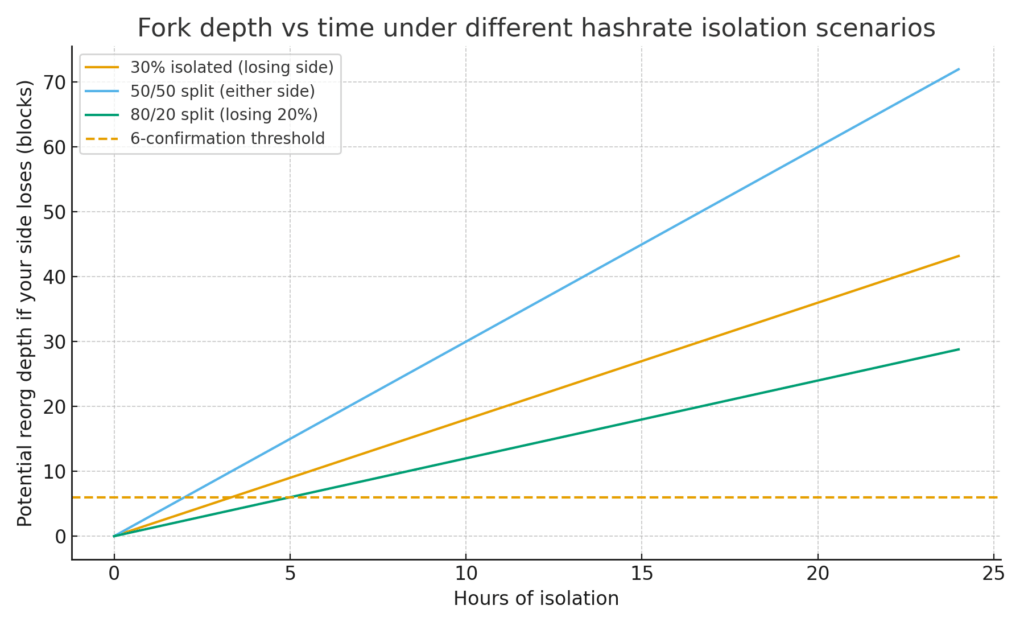
The dynamics are easier to reason about by modeling isolation as a percentage of reachable hashrate rather than by counting hubs.
With 30 percent of the hashrate isolated, the minority side would add roughly 1.8 blocks per hour. This means that a standard six-confirmation payment within that partition becomes at risk after approximately three hours and twenty minutes, as those six blocks can be orphaned if the other 70 percent of the network builds a longer chain.
In a near 50/50 split, both partitions accumulate similar work, so even short splits create competing “confirmed” histories on both sides, and the outcome on reconnection becomes stochastic.
In an 80/20 split, the majority partition almost certainly wins; the smaller partition’s blocks, roughly 29 after a day, would be orphaned on merge, reversing many confirmed transactions in that region.
Resilience tools do exist, and they shape the real-world impact.
Satellite downlinks, high-frequency radio relays, delay-tolerant networking, mesh networks, and alternative transports, such as Tor bridges, can carry headers or minimal transaction flows across damaged routes.
These paths are narrow and high-latency, but even intermittent cross-partition propagation reduces fork depth by allowing some fraction of blocks and transactions to leak across.
Miner peering diversity, multi-homed exchange infrastructure, and the geographic spread of pools increase the likelihood that at least some work propagates globally through side channels, thereby limiting the depth and duration of reorganizations when the backbone returns.
The operational guidance for market participants during a network fracture is straightforward.
- Halt cross-partition settlement, treat all confirmations as provisional, and harden fee estimation against local spikes.
- Exchanges can switch to proof-of-reserve attestation without active withdrawals, extend confirmation thresholds to account for minority-partition risk, and publish deterministic policies that map isolation duration to the required number of confirmations.
- Wallets can surface clear warnings about regional finality, disable automatic channel rebalancing, and queue time-sensitive payments for rebroadcast on recovery.
- Miners should maintain diverse upstream connectivity and avoid manual overrides that deviate from standard longest-chain selection rules during the reconciliation process.
The protocol survives by design because nodes, once reconnected, converge on the chain with the most accumulated work.
The user experience does not fare as well during the split, since economic finality depends on consistent global propagation.
The most credible worst-case scenario under a day-long multi-hub outage is a temporary collapse in cross-border usability, a sharp and uneven fee shock, and deep reorganizations that invalidate regional confirmations.
When links are restored, software resolves the ledger deterministically, and services restore full functionality after operational checks.
The last step is reopening withdrawals and channels once balances and histories are coherent on the winning chain.
That’s the recoverable case, but what if the fracture never heals?
What would happen to Bitcoin during World War 3?
Now then, what if those backbone hubs I mentioned at the start never come back?
Well, in that dystopian scenario, Bitcoin, as we know it, does not reemerge.
You get permanent geographic partitions that behave like separate Bitcoin networks, sharing the same rules but no communication between them.
Each partition continues to mine, adjusts its difficulty on its own schedule, and develops its own economy, order books, and fee market. There is no mechanism to reconcile histories without restoring connectivity or coordinating a manual choice of a single chain.
Here is what that steady state looks like.
Consensus and difficulty
- Until each partition reaches the next 2016-block retarget, block times run slow or fast according to the reachable hashrate. After the retarget, each partition re-centers around 10 minutes locally.
- Using our approximated shares, the expected time to the first retarget is:
| Partition | Hashrate share | Blocks/hour | Blocks/day | Days to 2016 blocks (first retarget) |
|---|---|---|---|---|
| Americas | ~45% | ~2.7 | ~64.8 | ~31 days |
| Asia/Oceania | ~35% | ~2.1 | ~50.4 | ~40 days |
| Europe/Africa/Middle East | ~20% | ~1.2 | ~28.8 | ~70 days |
After that first retarget, each partition produces blocks at roughly 10 minutes, then continues halving and adjusting independently.
Halving dates diverge by wall-clock time because each region reaches halving heights at different speeds before its first retarget.
Supply and “what is BTC:” Fees, mempools, and payments
Inside each partition, the 21 million cap still applies per chain. Globally, the total number of coins across all partitions exceeds 21 million, as each chain continues to issue subsidies independently. Economically, this creates three incompatible BTC assets that share addresses and keys but have different UTXO sets.
Keys control coins on every partition simultaneously. If a user spends the same UTXO in two regions, both spends are valid on their respective local chains, resulting in permanent “split coins” with the same pre-split history and divergent post-split histories.
- Mempools are local forever. Cross-partition payments do not propagate. Any attempt to pay someone in another partition never reaches them.
- Fee markets settle into local equilibria. The smaller-hashrate partition tends to have tighter capacity during the long pre-retarget period, then normalizes after difficulty adjusts.
- Lightning channels that span users across different partitions cannot be routed. HTLCs time out, peers publish commitments, and closures confirm only in the local partition. Cross-partition liquidity becomes stranded.
Security, markets, and infrastructure
Each partition’s security budget equals its local hashrate and fees. A region with 20 percent of pre-split hashrate has a lower absolute cost of attack than the global network did. Over time, miners may migrate toward the partitions with higher coin price and cheaper energy, changing the security profile again.
Without a path for headers between partitions, an attacker in one partition cannot overwrite the history in another; therefore, attacks are contained within a specific region.
- Exchanges become regional. Tickers diverge. You effectively get BTC-A, BTC-E, and BTC-X prices, even if all refer to themselves as BTC locally.
- Fiat on-ramps, custody, derivatives, and settlement rails specialize in regional chains. Index providers and data vendors have to choose one chain per venue or publish multiple composites.
- Bridged assets and oracles that depended on global data feeds break or fork into regional versions.
Protocol rules remain the same unless a partition coordinates a change in the rule. Any upgrade adopted in one partition does not activate elsewhere, creating rule-set drift over time.
Pool software, explorers, and wallets run per-partition infrastructure. Multi-homed services cannot reconcile balances across chains without a manual policy.
Can the partitions ever reconcile without those hubs?
If no communication path is ever restored, protocol convergence is impossible. The only way back to a single ledger is through social and operational means, for example, a coordinated selection of one partition’s chain as canonical and the abandonment or replay of the others.
Given deep divergence after weeks, automatic reorg to a single history is not feasible.
Operational takeaway
We would have to treat a permanent fracture exactly like a hard fork with shared pre-split history. Manage keys so you can spend split coins safely, avoid accidental replay across partitions by using outputs that only exist in one region, and maintain separate accounting, pricing, and risk controls per partition.
Miners, exchanges, and custodians should select a home partition, publish chain identifiers, and document policies for deposits and withdrawals specific to each chain.
In short, if those hubs never return and no alternative paths bridge the gap, Bitcoin does not die; it becomes several independent Bitcoins that never rejoin.
The post Inside Bitcoin’s 24 hour race to survive a global internet blackout appeared first on CryptoSlate.